Kubernetes debug story
Side effect of a privileged container
Kubernetes has changed how we operate services in production by providing a powerful API allowing efficient managing of workloads. Our team started the Kubernetes journey a few years back and over the course of time, we have had some interesting debugging stories.
Qasim Sarfraz
Apr 26, 2021 . 6 min read
How do we run Kubernetes?
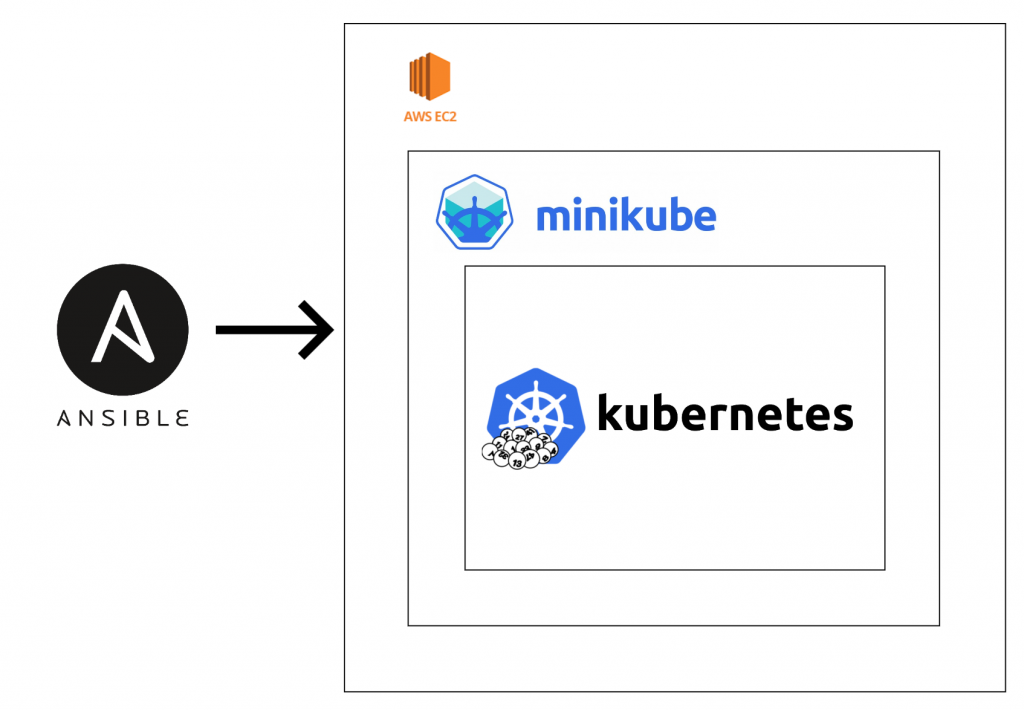
Before jumping into the actual story, I want to talk about our setup and workflow around using Kubernetes. As a developer, you can have your dedicated Kubernetes environment enabling independent running and testing of your services. We have a job that can spin up a single-node Kubernetes cluster in a given cloud provider using ansible. The job is taking the desired Kubernetes version as a parameter and uses minikube driver none to set up the environment so everything runs on the host directly.
We have some helpers container running on these hosts e.g VPN server so that you can directly connect to the services to ease the development experience. There is automation around deploying a set of services to a given instance. This allows us to have a clean workflow to quickly spin up a subset/complete platform for testing. The same setup is used in integration and CI/CD pipelines so getting feedback on a Kubernetes release can be as easy as changing a variable. Also, having the ability to test the Kubernetes manifests for all the services on a fresh cluster gives us the ability to stay on track for the Blue/Green style Kubernetes upgrades. The versions for different components used during this story are as follow:
Let’s jump to the story now. I triggered the job to get me Kubernetes environment and everything went as expected with all the ansible tasks green in the logs:
After seeing the logs I figured out immediately that it was etcd, because of 2379 port. So I jumped to etcd logs and realized it has issues listening on 127.0.0.1, which already made me think I am in for a long fun day with logs showing:
2021-03-14 12:24:05.094337 I | embed: ready to serve client requests
2021-03-14 12:24:05.095585 I | embed: serving client requests on 127.0.0.1:2379
WARNING: 2021/03/14 12:24:25 grpc: addrConn.createTransport failed to connect to {127.0.0.1:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial tcp 127.0.0.1:2379: i/o timeout". Reconnecting...
WARNING: 2021/03/14 12:24:46 grpc: addrConn.createTransport failed to connect to {127.0.0.1:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial tcp 127.0.0.1:2379: i/o timeout". Reconnecting...
WARNING: 2021/03/14 12:28:34 grpc: addrConn.createTransport failed to connect to {127.0.0.1:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial tcp 127.0.0.1:2379: i/o timeout". Reconnecting...
2021-03-14 12:30:25.571579 N | pkg/osutil: received terminated signal, shutting down...
2021-03-14 12:30:25.571910 I | etcdserver: skipped leadership transfer for single voting member cluster
WARNING: 2021/03/14 12:30:25 grpc: addrConn.createTransport failed to connect to {127.0.0.1:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial tcp 127.0.0.1:2379: operation was canceled". Reconnecting
Assuming something basic was wrong I had to jump to basic tooling and ping/tcpdumpcame to my mind. I ran both of the tools:
$ ping 127.0.0.1 -c 1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
--- 127.0.0.1 ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
$ sudo tcpdump -n -i lo icmp
12:40:30.458147 IP 192.168.117.1 > 127.0.0.1: ICMP echo request, id 9782, seq 1, length 64
ICMP traffic on 127.0.0.1 was being dropped but at least it showed something to the source IP address was happening. Where 192.168.117.1 was an alias address for the loopback interface.
This was the time to check the firewall since I was running iptables. By listing the rules I figured out the rule that was the cause of dropping packets. The rule was recently added to Kubernetes as a security fix:
Chain KUBE-FIREWALL (2 references)
target prot opt source destination
DROP all -- anywhere anywhere /* kubernetes firewall for dropping marked packets */ mark match 0x8000/0x8000
DROP all -- !loopback/8 loopback/8 /* block incoming localnet connections */ ! ctstate RELATED,ESTABLISHED,DNAT
As the rule clearly states that it drops all non-loopback packets so packets and the source address 192.168.117.1weren’t going to bypass the rule. Since the fix was recent I had no clue which/when part of my installation was broken in the past. But I knew that it might be a consequence of some masquerading done by iptables.
$ sudo iptables -t nat -L POSTROUTING
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
KUBE-POSTROUTING all -- anywhere anywhere /* kubernetes postrouting rules */
MASQUERADE all -- 172.66.0.0/16 anywhere
$ sudo iptables -t nat -L KUBE-POSTROUTING
Chain KUBE-POSTROUTING (1 references)
target prot opt source destination
RETURN all -- anywhere anywhere mark match ! 0x4000/0x4000
MARK all -- anywhere anywhere MARK xor 0x4000
MASQUERADE all -- anywhere anywhere /* kubernetes service traffic requiring SNAT */
But there wasn’t any rule for loopback traffic. I even added some tracing to find more details but it didn’t help since you can’t trace filter type nat. All it showed was source IP address was modified already:
But it was a time to take a step back and try to figure out which component might be causing it. I tried cleaning up the instance i.e deleting minikube, flushing iptables etc but the source address stayed broken. So after frustrating attempts, I reboot the instance and voila the source address was fixed.
Now I had a way to toggle between healthy and broken states. It was time to observe the installation step by step and see what part was causing the issue. I started my ping/tcpdump and along that started the playbook. The source address stayed 127.0.0.1 during minikube installation but once the playbook to install helpers container kicked in the address changed and hence the cluster was broken. One of the containers was an openconnect server that had the following in the entrypoint script:
# Open iptables NAT
iptables -t nat -A POSTROUTING -j MASQUERADE
iptables -A FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
That rule was the culprit, after removing it the communication on the host resumed and everything worked as expected. Also, the cleanup wasn’t deleting these rules so a reboot was the only way to get rid of them initially.
Now I wanted to understand why I wasn’t able to see these rules on the host. I checked the version for iptableson the host and in the container using:
The container image I was using was Debian Buster, reading therelease notes I realized they switched to a new backend for iptables with the same command-line interface:
Network filtering is based on the nftables framework by default in Debian 10 buster. Starting with iptables v1.8.2 the binary package includes iptables-nft and iptables-legacy, two variants of the iptables command line interface. The nftables-based variant uses the nf_tables Linux kernel subsystem. The alternatives system can be used to choose between the variants.
For me, it meant that with nf_tables the container was using an updated iptables backend which the host had no idea. Hence none of the rules were shown on the host. There are a couple of solutions to avoid such a situation.
Upgrade the host to use the nf_tables backed iptables.
Make container image to use legacy iptablesbefore adding any rules. For Debian Buster it can be done with the following:
With this, the fun story of debugging came to an end teaching me a lot about Linux networking and filtering. Playing with iptables from a container might not be a great idea since it requires advanced capabilities and privileges. Also, it might be a good hint for anyone who might see such issues after upgrading to Kubernetes v1.20+.