LOTTO24 took on the challenge and succeeded due to its collaborative approach and team spirit. We want to share three of the most accelerating turns we took when refactoring our monolith to microservices.
One of the first tasks when migrating to microservices is to split up your monolithic platform into small, logical connected chunks so that teams can work independently from one another.
Therefore, the first misconception is that a monolithic application needs to be “prepared” for a microservice by refactoring. This belief has been shared by consultants, partners, experts, and several blogs as learning when discussing migration issues.
At LOTTO24, we start such initiatives collaboratively. Once team members identify how to proceed towards a common goal, we discuss this at our weekly Competence Center Architecture (CCA) meeting, which is open for everybody to participate, propose and challenge new ideas and initiatives.
The proposal is simple. Microservices are “just” extracted code from a monolithic application. In the best case, the code is being extracted so that every team can build and release its features independently from another, without too much coordination. Great contract and API testing should secure the few boundaries that exist.
Indeed it can be quite useful. However, it should not be the priority!
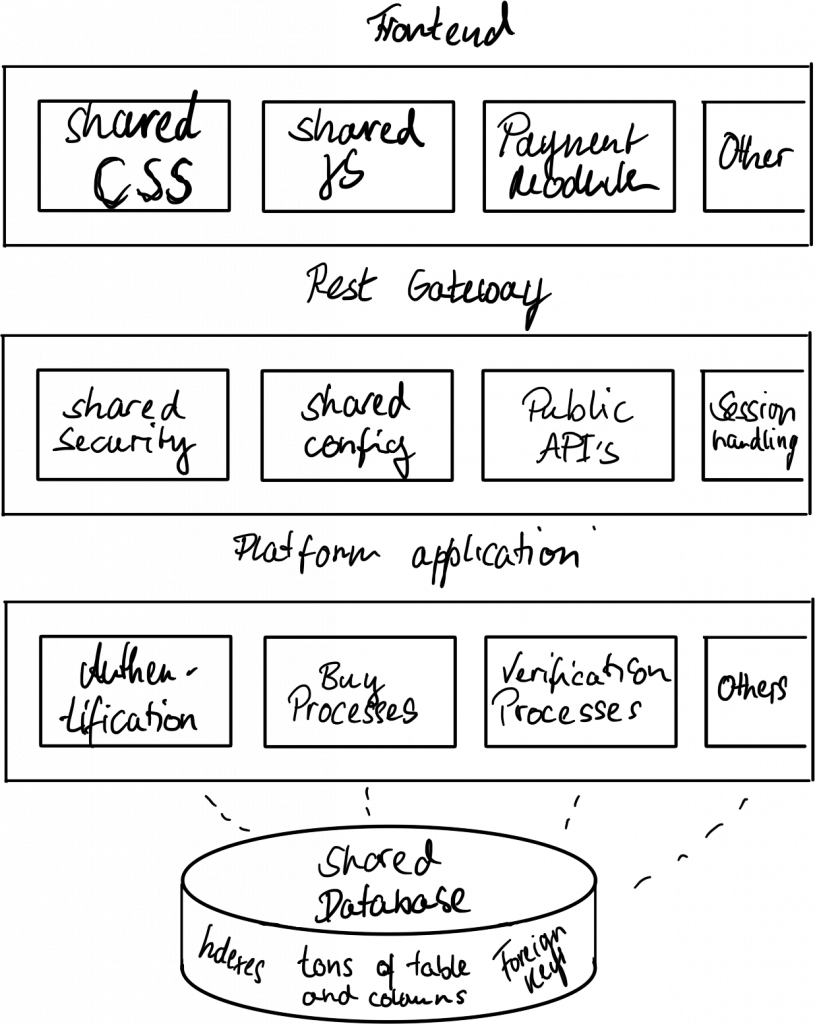
It turns out that the task is not as easy as it sounds. Let’s have a look at a typical monolithic platform:
As the illustration shows, the platform consists of four layers that all developers of the company contribute to:
– Frontend layer (Consists of shared CSS, shared JS, etc…)
– API layer (Consists of shared Security Configuration etc…)
– Platform layer (Consists of Database connection pools and all major features and processes)
– Database layer (Consists of all platform and data tables cross-linking each other)
Each of these layers will be individually altered and updated daily when teams serve new features and functionalities.
Typically monoliths employ dependencies across domains and team boundaries.
Imagine a payment service that should only accept new credit cards if a customer account is not blocked.
Services to manage account restrictions might be maintained by a customer team, while a payment team operates payment providers.
The payment team wants to enhance the security by verifying if a customer is not being blocked before accepting new credit cards as a payment method.
In a monolithic environment, the payment team would search for blocked states in the codebase and access code written by the customer team without further notice.
This way, over time, monoliths typically create a big network of cross-team dependencies that are hard to decouple and hard to manage.
As usual, a team suggested this approach and started an initiative supported by all engineering teams.
The initiative’s task was to extract and clean up the code to prepare the various modules for microservice extraction. How could that be done? The code was analyzed, and the initiative decided to start with our dear beloved customer object.
The customer object is a Database Entity Class in our monolith application that is used to reference customer data and settings. It was the most shared object in our platform code. It contains information about a customer such as the account status (e.g. blocked), the account’s e-mail address, a customer number, and links to customer preferences such as payment methods and limits.
Starting with the customer object was based on the assumption that this would be the hardest part to refactor. Since almost all our platform monolith code references the customer object, all the references would be cleaned up and replaced by references to a customer identifier once it is extracted. This will allow all the other teams to convert their functionalities and migrate them into microservices.
One of the problems with this approach is that teams tend to extend and alter existing code because it is a known workflow for them.
The approach, in general, is a great idea. However, to push through the initial refactoring takes quite a lot of time. And this is an issue.
Only once the customer object is extracted, teams commit to building functionalities with the new microservices patterns. Therefore groups, whose code is not yet refactored, tend to continue adding features into the monolithic layers due to priorities.
Every team which demands to add new features also requires to add new dependencies to the customer object growing the work that the initiative does. Various teams adding dependencies on a daily basis is faster then the initiative work force trying to clean up cross-team references.
Quickly, it was clear that the initiative can not work faster than the rest of the company.
Still, though, the team discussed to go in smaller iterations and refactor feature by feature. However, the code consisted of so many transitive dependencies that this turned out to be impractical.
So why not start somewhere else?
Even if the initiative would have started somewhere else, the teams needed the customer object to get specific information and store data alongside customer accounts. Groups still preferred to add those functionalities to the existing monolithic application rather than inventing the best practices needed to link those data.
As good engineering practice shows, it’s good to take a step back and review the approach. Initially, the team shared its struggles along the way again in our weekly CCA meeting and discussed the various teams’ topics.
The approach was challenged, and another proposal was made. Why not adding a microservice infrastructure that allows teams to easily add new features without altering the monolithic layers in the first place.
Adding such a system would allow teams to add new features without interrupting or interfering with the big refactorings necessary to restructure the legacy code.
Priorities shifted, and another initiative came up to contribute.
Convincing teams to change their development habits and to explore new best practices, is only successful if building microservices is a lower investment than altering the current monolith.
Let’s review what exactly the teams need to work independently from each other and prepare a concept that allows teams to utilize microservices with almost zero additional effort.
It turns out that the requirements for creating new services are quite simple:
– exposing public APIs securely to integrate new features for the frontend
– being able to deploy independently
– easy communication among services
– frontend adaptions (skipped for the first iteration)
However, simple does not mean easy. With each service being operated independently and fault-tolerant, easy communication and exposing APIs is quite more difficult.
We wanted to create an infrastructure that supports the positive aspects of microservices (such as fault tolerance) and mitigates the harmful elements (increased complexity due to networking, authentication, etc.).
A well designed microservice architecture is fault-tolerant, it operates services independent from each other. If a service suffers from outages, the rest of the general application sustains its operations.
Besides this, well-designed microservices can be deployed independently from the rest of the application.
All of these benefits are achieved by utilizing the benefits of distributed systems and networking. However, this also increases complexity especially due to inter-service communication and networking.
A well-designed microservice-capable infrastructure should support the strengths of individual deployments and fault tolerance, but mitigate the networking and inter-service communication overhead.
We defined our domains and came up with the following intermediate step in our architecture that supported adding microservices without altering our monoliths.
So let’s review the prerequisites to allow easy alteration of the features of the platform.
First, it was essential for us that every team can create public APIs. The reason why this was so important to us was that during this period, adding APIs to our platform for new features was a widespread and common task every team had to do. Teams needed to store data for customers and provide read and write access to the newly introduced features, for example, to request and edit E-mail notification preferences.
However, we did not want to compromise on security. We seek to provide our site reliability and operations teams the ability to review and search APIs easily.
Even more critical, we technically wanted no request to pass to the platform if a customer did not authorize it. So we built vital security checks into our new API gateway.
During that time, our platform was already progressing to Kubernetes and Infrastructure as Code, which we wanted to leverage.
Instead of building an API gateway that hardcodes each URL for a public API and requires wiring up all connections between the public API and the microservices manually, we wanted to leverage our Infrastructure as Code and the capabilities of Kubernetes to discover and expose our public APIs.
We saw many microservice architectures fail due to the manual effort and overhead introduced by mapping internal to external APIs and keeping those mappings in sync and up to date. This misconception would violate the independence of a microservice architecture to allow changes without inter-team dependencies.
Last but not least, we reviewed one of the reasons why teams shared code in the first place. As highlighted in the previous “business won’t stop” section, the team creates cross-references to access relevant account or customer information. Every service needs to check individual account states and data.
- discovers public API’s from microservices and expose them securely
- must authorize and verify every API Call to a microservice.
- must discard unauthorized requests and prevent them from entering microservices (to catch specific attack scenarios)
- must validate permissions to specific roles
- must maintain roles and permission at a central place
- must share session-relevant data among microservices without frequent requests to the backend to keep the networking footprint small
- should expose APIs without further deployments of the API gateway to avoid cross-team dependencies and allow independent releases.
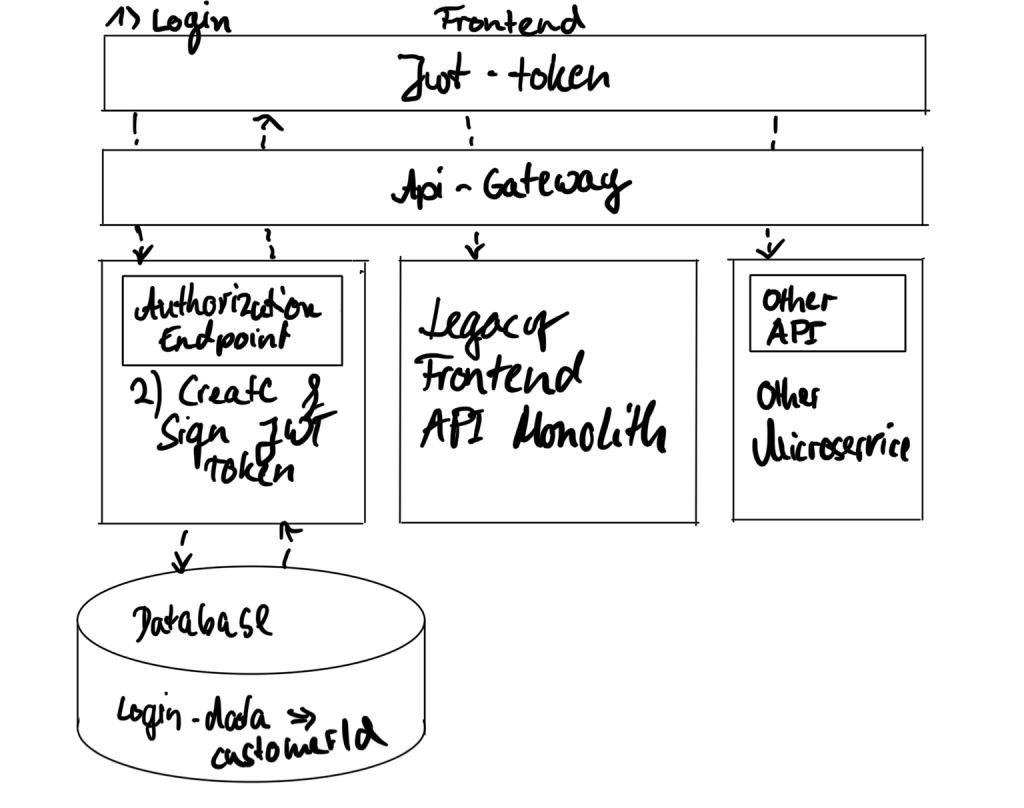
Login process in a stateful monolithic application
- As many monolithic applications, the prior LOTTO24 shop provided a login endpoint based on HTTPS to allow customers to log in.
- The login credentials are verified against those a user has stored in their account. Once that verification passes, a session is established, and a non-guessable session identifier is shared with the backend and the customer’s browser.
This article will not go too deep into the specifics of session management and JWT tokens. However, we selected JWT as a technology for authorizing our API requests for the following reasons:
- JWT allows to store session data and is cryptographically signed.
- JWT allows avoiding unnecessary roundtrips in microservices
- JWTs are standard and widely used on the web with various support of frameworks and tools.
We also know about the general concerns towards client based authorization but adapted best practices to mitigate those:
- JWT tokens can not be immediately revoked
We have certain invalidation methods implemented, allowing invalidation of JWT tokens without increasing the system’s load.
Additionally, we utilize short-lived expiration times on access tokens and revalidate sessions during token refresh.
Overall, the benefits of using JWT for a scalable microservice architecture are worth the additional efforts to invalidation and verification.
JWT tokens now provide our microservices with the relevant metadata to process or store data for a certain customer.
This is how a typical JWT would look like:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
If this token is being decoded, it looks like this:
{
"sub": "1234567890",
"iat": 1516239022,
}
The sub (subject) adds a customer identifier while iat (issued at) indicates when the token has been created.
JWTs can be extended by custom claims to add certain account information such as restrictions or preferences.
A JWT is cryptically signed, so it can be trusted once its signature is being verified.
Tokens will be signed by appending a signature. The format looks like the following:
<header>.<token-data>.<signature>
The signature will sign the provided token-data during the token creation process on the platform.
Token data and a signing key will be used in order to calculate the signature. Once token-data changes, the provided signature will change.
During their startup, microservices will fetch a verification key. This allows to check whether the signature matches the token-data and is being signed by the original signing key.
With this signing process, contents of the JWT token data can be trusted without further networking.
This allows microservices to avoid further requests to resolve session data and mitigate the added load through the loss of a shared global state of a monolithic application.
Microservices now can store data to this customer identifier in their own databases.
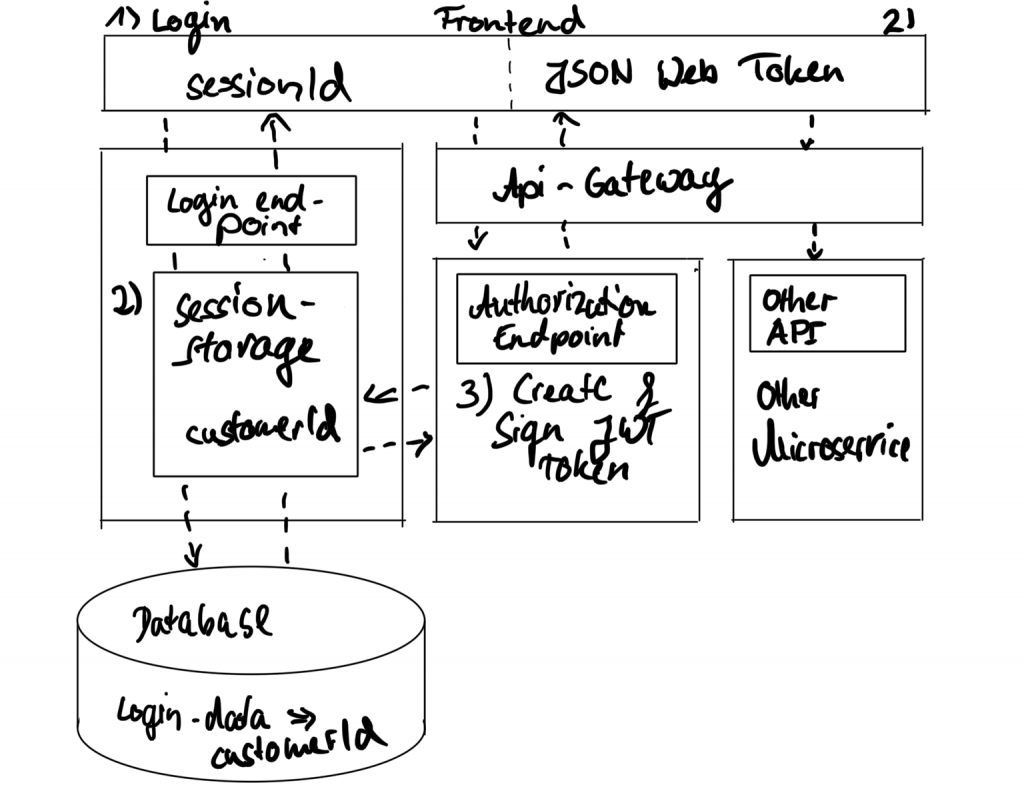
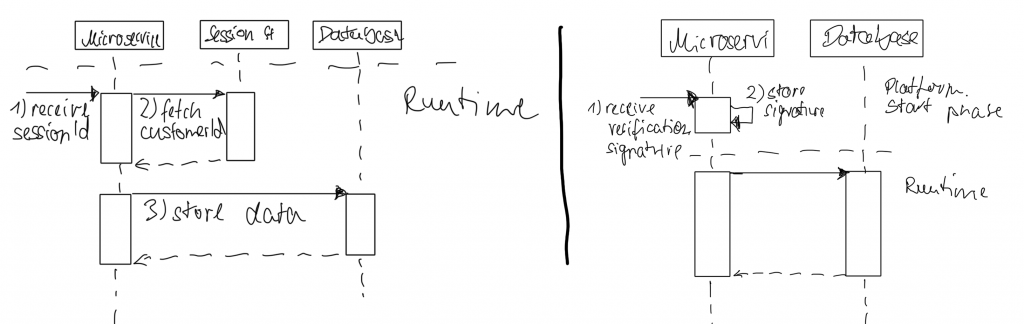
Let us compare a request flow of storing data for a customer with a typical session-id based authorization compared to a flow with JWTs.
On the left side of the image is a classic session-id flow. In this scenario, a microservice receives a session-id (1). session-ids, though, are not fixed and change over time for security reasons. Every customer login creates a new session-id. So this is not an identifier that can be used to store customer data, apparently.
Therefore, the microservice would need to access and fetch the current customer number associated with a session in order to persist data.
This actually forces every microservice to make one additional request per HTTPS call, effectively doubling the internal platform traffic.
It also forces every microservice to create connectivity to the session storage and engages every microservice to know about session management details. This is something to avoid.
In contrast, on thr right side of the image, the microservice receives a signature once the platform starts. This allows microservices to verify HTTPS calls and their respective tokens for authenticity.
If a token is authentic and its token signature matches the calculated signature, the token contents can be trusted because it’s guaranteed, generated by our platform.
This is reducing the microservice platform’s internal load and cutting cross-service dependencies.
However, we do not want to rely on security on all individual microservices. Chances that signature verification will be forgotten are simply too high.
That’s why another essential component is being introduced:
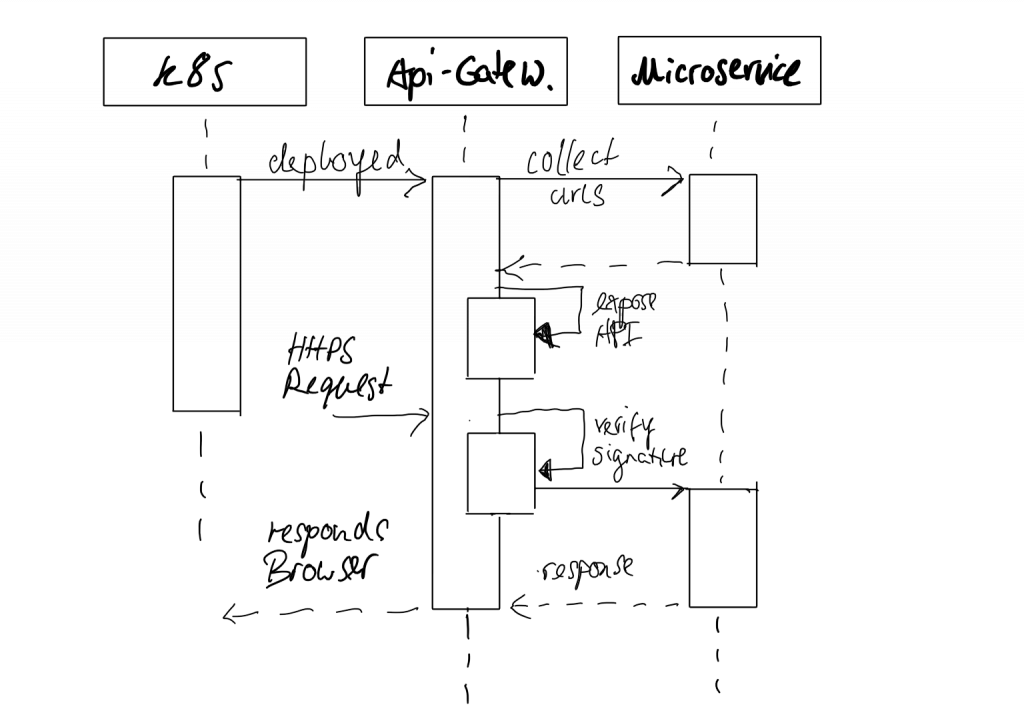
To ensure every request is properly signed and validated, we introduced an API gateway that acts as a proxy and validates requests.
This API gateway is the most considered element. It acts as a firewall for malicious requests, should revoke unauthorized requests, and expose public APIs from the various microservices.
The API gateway runs under a certain domain that the browser can access to execute HTTPS requests, fetch data, change them, or initiate purchasing processes.
It will receive these requests and forward them to the right microservice if they satisfy the authorization requirements.
We use Infrastructure as Code and Kubernetes to discover platform events such as a microservice being deployed or removed from our gateway.
We analyze our platform configuration and scan the configured microservices for public API endpoints to be exposed based on those events.
Kubernetes offers an Event API that allows subscribing to those deployment events.
With that API, we can discover new services once they are deployed and mount their REST endpoints into our public gateway.
This way, we allow teams to deploy API changes and update independently.
To sustain security, the API gateway will still restrict the traffic. Even though microservices are allowed to publish APIs, they will not receive any unauthorized requests. This balance is a neat decision allowing for great flexibility and independence while sustaining strong security.
Of course, this is not the only security mechanism in place. As any public website should have, LOTTO24 operates various security mechanics on multiple layers of the software stack.
However, having a single point of authorization and access validation ensures that only customers with validated and authorized sessions will be able to access their own data!
Everything described in this post was a long journey.
We were glad that we were backed by investments also to our infrastructure and monitoring.
Our teams worked in parallel on Kubernetes due to the higher demand for platform virtualization and inter-service communication. They improved monitoring by offering features such as request tracing and real-time logging and monitoring.
It was crucial for success, that those initiatives were running almost in parallel and that they also each had enough manpower to provide the right tools, features and adjustments at the right time.
Also our adjustments and additions were carefully considered. We always developed the most demanded features and integrations from our engineering teams in order to incentivise them to prefer the microservice infrastructure over the monoliths and its release trains.
Last but not least, we always cleaned up during that journey. If such an adjustment is being made for the right time and the right moment the developers will need to do compromises.
We were also willing to implement shortcuts, but only when it didn‘t harmed the customer. It harmed us for a while with additional maintenance efforts, but was required to quickly offer teams the tools and services they needed. In sum, the shortcuts and additional maintenance and costs was lower then fighting against windmills, if teams would have continued working with the legacy architectures.
But also this was only possible, due to the time we used on every single step to streamline before we went on the the next adjustment or shortcut.
Today, we do not only have an additional infrastructure for microservices – we also cleaned up and the isolated the authorization as a microservice of its own. This allows us to scale our login and easily add new authorization methods without altering any other microservices. The intermediate step of mixed session-id authorization and JWT token authorization is cleaned up:
LOTTO24 does not only operate on the cloud and enjoys the increased scalability options provided by its microservices today.
Also development speed and site platform reliability increased.
The journey has just begun and the next steps are yet to come…